
The runtime configuration problem
Here’s an interesting problem: suppose you have an event-driven system that needs to respond to events in while the system is running, as they happen, and the responses themselves are based on a configuration of rules that can be changed while the system is running, from a configuration user interface. The changes are infrequent and manual, and done by a human. The problem is this: since reloading the latest configuration always takes time, how do you build the runtime configuration capability without causing performance problems in the event processor?
A good example of this is some business rule engine that performs actions based on users interacting with a system. The rules for these actions are configurable in a separate application, like a web interface, doesn’t matter. The application configures the ruleset and the engine executes them. Once the rules are in effect, the engine is suppose to reflect the new configuration immediately.
Let’s call the engine an event processor and the configuration application as the configuration tool. The task of the event processor is to respond to events flowing in from the surrounding environment. Concretely this could mean an event stream of some kind, let’s leave that abstract. It doesn’t matter where they come from or what the events are, we simply need to assume that the system has to respond to each one of them. The responses are based on business logic executed according to a configuration. This configuration is updated by humans
Since the configuration will always live in some external storage system for persistence purposes, there is a cost for retrieving the data from this storage system. We want to minimize the costs occurring from retrieving this configuration data while keeping the system as accurate as possible. With accuracy I mean once the configuration tool is used to update the system configuration, the event processor respects those updates. What we also want is to make the configuration as easy as possible. The sequence diagram in Figure 1 illustrates how the event processing and rules are tied together.
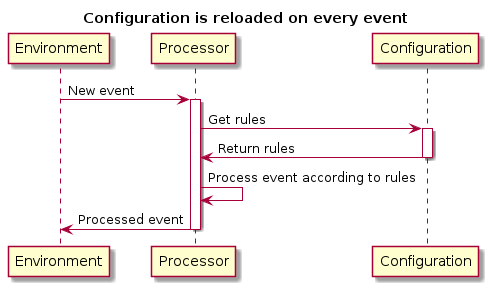
We judge the system by three metrics:
-
Usability: how easy it is to update the configuration?
-
Accuracy once updated, how quickly are the configuration updates reflected in the results of the event processor?
-
Performance: how well does the event processor scale in performance when the amount of incoming events increases?
The combination of the event processor and the configuration tool forms a system. We want to keep this system as performant, accurate, and user friendly as possible. There are several ways to do this.
No caching, reload on every event
The naïve approach is to fetch configuration on every event. This would cause a database fetch on every event. This is most likely the scenario we want to avoid, but it is not without merit. The changes are reflected immediately. The database engine might be able to cache repeated reads and optimize the read latency.
This approach has the maximum accuracy, but contains potential performances problems. The system is accurate, the configuration update immediately alters the behavior. The configuration tool is also usable since its usage has an immediate effect.
Keep in mind that out of all the listed approaches in this post, this might be the simplest and most reliable out of all. After all, reading data is relatively cheap, and modern RDBMSes have robust caching algorithms.
That said, this approach smells. For $n$ events you get $n$ calls, and we know that the frequency of configuration updates is much, much less than $n$! So in terms of performance, this might not scale that well.
Nonetheless, we can try minimizing calls to the database. There are two simple solutions: local and temporal caching. While I mention caches, I do not mean implementing your own full-fledged caching system, since that is always a bad idea, I mean implementing application logic that transparently prevents excessive calls to the database.
Invent a code-level cache
One approach, if we are talking about plain RDBMS reads, is to use temporal versioning in the configuration data. This works when the query to fetch the whole configuration data is complicated and time-consuming, but the query to fetch one single column is cheap. For instance, consider this pseudoish Scala code:
def getConfiguration(database: Database): Configuration = {
val knownModified = lastModified.get()
val dbLastModified = database.getLastModified()
if (knownModified >= dbLastModified) {
// return current config
currentConfiguration.get()
} else {
// fetch new config and save it to our cache variable
val newConfig = database.getConfig()
lastModified.setAtomically(newConfig)
newConfig
}
}(Readers, please ignore purity and referential transparency.) Upon every call to
getConfiguration, the code fetches a date-time value from the database and
compares the version of the data we already have. If the data is out of date,
the data is reloaded from the database, otherwise the old data is returned.
This is a naive code-level cache, and it’s very simple. But it turns out to work nicely even in a distributed scenario: provided the write operations are handled properly, no single instance of the application will end up having mixed configuration data at time instant \(X\).
In terms of usability, this is completely transparent to the user. Just click "Save" and the configuration is updated. Its accuracy is also in line with the naïve method, but it still causes one database read operation on every event. Although smaller, the performance cost still scales linearly with the number of incoming events.
Use timers
Timed reads are also possible. You can set an arbitrary refresh interval and indicate to your users that you need expect configuration data to be in effect every X seconds or so. This makes the whole data reading problem go away but no longer makes it possible to do real-time adjustments. For some systems this can be unacceptable, though I think for most business-oriented products this is more than acceptable.
The interval caching, that is, timed refreshes every $t$ seconds is a way to ensure the amount of database reads is fixed. For instance, imagine our naive scenario whereby the database is accessed upon every request, and imagine if the event processor would handle thousands of requests per second!
The acceptability of this solution depends on the use cases of the application. Is the application supposed to react instantly to configuration changes? Is there any tolerance to a latency between the instant the changes were effected and between the instant they are actually used? If there is a tolerance to a latency of $t$ seconds — meaning, the users of the application can be told somehow that "changes might take $t$ to come into effect", then this solution might be one of the simplest. Even having the shared refresh interval to be 1 second will never burden the database and yet at the same time be acceptable to the end users.
Yet, the application has to concede that it’s no longer operating in real time. Informing that changes might take some time to come into effect can give the impression that the system is slow. That said, the interval can be in the second or sub-second range. All we want is to limit the number of database reads to some linear value, instead of scaling with the amount of incoming requests. So even using a fixed interval of 100 seconds means at most 600 requests per minute, which is not a lot for any modern database. And you can go lower, increase it to 6000 per minute. So at that point telling the users that their changes might take up to 100 milliseconds to come into play would be pointless, depending on context. For 99% of the user-facing applications this is a perfectly acceptable method unless there is absolutely no tolerance, not even in the millisecond range, for latency. In that case other alternatives must be pursued.
With a timer approach we’ve got user-friendliness at maximum, since there is still a "Save" button, and it works in real time[1], that is, the application need not be restarted for the configuration to take effect.
Staged read-only configurations
The other solution would be to make the system “staged” – configuration cannot be updated in real time, the event processor loads the data in memory at application startup, and any alterations to the configuration requires restarting the system. But this system is no longer “live”, and requires the extra restart step from its users. On the other hand, there are no performance implications, since the data is in memory for fast access.
From a usability perspective I would rate this lower than the previous approaches since it requires manual deployments. You must now decide if you can live with downtime or not. Without downtime, you must use some sort of rolling restarts. This incurs an accuracy penalty, since some systems not yet restarted might process events using a configuration that is out of date. Or, you go for the downtime approach, which has no accuracy penalty, but might be unacceptable from a business or usability perspective.
Use a real cache to get fast reads
Another solution would be to cache the configuration data into a fast in-memory database, where reads are cheap, and have the configuration data trickle there from the master database. But this installs a failure point and potential consistency issues (how do you ensure this works when the system is distributed?) and requires careful engineering to work reliably and efficiently.
This is much like the first approach, a complete read for every event, but the external cache attempts to minimize the cost of the read operation. This gets us maximal accuracy and user-friendliness, but the performance aspect now becomes murkier. Are there limits to the caching system? Can we rely on it in 100% of calls?
This also introduces latency to the question of accuracy: data between the principal system and the cache must be kept in sync. The speed at which that happens must be instantaneous. Is that guaranteed? Does this work when the data systems are distributed across the globe?
What is more, this is just moving the problem around (see truth 6). I don’t want to do that unless absolutely necessary. I certainly don’t want to be answering the above questions.
Conclusions
This presents a tough problem for use cases when a system is in continuous operation. From my experience, usually the simplest solution is the best. I’ve found any of the first four solutions to work adequately, but they all have different impacts on the end users. I’ve had bad experiences by using external caching applications (like Memcached) in front of read-only data from databases, as they introduce points of failure and introduce operative overhead.
I would recommend starting with the naïve approach first, no caching. When or if that becomes too much, only then try some of the other approaches. The code-level cache is easy to implement using STM. The timer-based approach works well if your application permits some latency in its operating mode, which is most likely the case for most user-facing applications out there.
I’m certain there are more ways to solve this problem, but after a round of searching I couldn’t really find anything. If any reader has some ideas, do not hesitate to email me with them!